近日遇到一个诡异的问题(后续更新),于是探究了 Runtime 中 Class 的一些细节。该探索过程以 NSClassFromString 为入口,因而需要知道它的具体实现来得到一条严谨的线索。本文则记录了该次探究过程中对 NSClassFromString 的调研,从其汇编代码推测对应的 OC 实现。
首先来看 NSClassFromString 声明如下:
1 | Class _Nullable NSClassFromString(NSString *aClassName); |
由于 Foundation.framework 并没有开源,所以没有办法从源码的角度分析其实现细节。因此这里通过一个取巧的方式来取得它被编译得到的汇编指令:在 Demo 工程中对 NSClassFromString 进行调用,然后通过设置符号断点 Hook 住调用处,可以得到它在 x86_64 架构上对应的汇编指令:
所用测试代码如下:
1 | // main.m |
👇🏻
汇编代码,长图折叠

下面开始依靠着我薄弱的汇编知识对这份汇编代码进行分段分析:
分段分析
Part 1
首先看开头的这一部分汇编指令(<+0> ~ <+40>),前面是一波压栈的操作,到了图中红线框选的地方执行了一次 testq 指令:
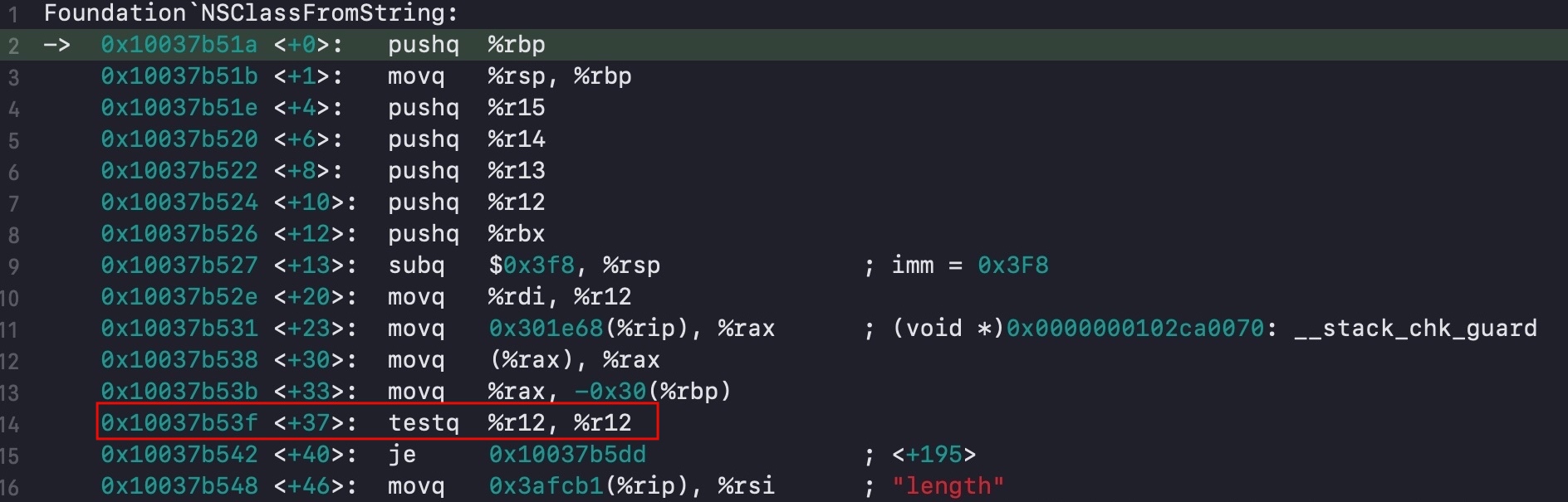
testq指令表示将两个四倍字长(64 bit)的数字进行逻辑与操作,如果结果为0则 ZF(Zero flag) 设置为1,否则设为0。标志寄存器rflags用于存放这些标志,ZF 位于第 7 个二进制位。
由于上面的 movq %rdi, %r12 指令,这里 r12 具有与 rdi 相同的值,也就是 @"BigDog"。
x86_64 架构中
rdi寄存器用于存放函数调用的第一个参数。
1 | (lldb)register read r12 |
而紧接着下面一句执行了 je 指令。je 指令的会判断 ZF 标志位是否为 1,是则跳转到目的地址 0x10037b5dd,位于这份汇编指令的后段,下面会详细分析。所以这两行指令的意思是:如果 NSClassFromString 的参数为 nil(自身逻辑与结果为 0),则跳转到地址 0x10037b5dd。
小结
对应 OC 代码:
1 | // Part 1 Code |
Part 2
紧接着看下面这几个指令 <+46> ~ <65>:

在跑到 callq 指令的时候输出 rdi,rsi 以及 rbx 三个寄存器的内容:
1 | rdi = 0x000000010b2ff030 @"BigDog" |
x86_64 架构中
rdi寄存器用于存放函数调用的第一个参数,而rsi则存放第二个参数。而rbx则用作数据存储,用途视调用者而定,也就是说瞎 JB 用。
小结
所以这部分指令的意思是通过 objc_msgSend 进行消息发送,转换为对应的 OC 代码就是:
1 | // Part 2 Code |
最后通过 movq 指令将结果 6 存到了 r14 寄存器。
rax寄存器用于保存函数调用的整型或指针返回值。
Part 3
再来看下一组 <+68> ~ <+99>,在跑到下面这行指令的时候输出一些寄存器的内容:

寄存器内容:
1 | rdi = 0x000000010b2ff030 @"BigDog" |
x86_64 架构中,
rdx,rcx以及r8这三个寄存器分别用于存放函数调用的第 3,4,5 个参数。而在objc_msgSend中的第 3,4,5 个参数对应的就是getCString:maxLength:encoding:方法被调用时的第 1,2,3 个参数。
getCString:maxLength:encoding: 方法的原型如下:
1 | - (BOOL)getCString:(char *)buffer maxLength:(NSUInteger)maxBufferCount encoding:(NSStringEncoding)encoding; |
rdx 的值是一个内存地址,也就是调用 getCString:maxLength:encoding: 函数时传入的第一个 buffer 参数;而 rcx 为 0x3e8 也就是 10 进制的 1000;最后 r8 寄存器的值是 4,对应枚举类型 NSStringEncoding 里面的 NSUTF8StringEncoding。
小结
所以这部分的等价 OC 代码就是:
1 | // Part 3 Code |
这条指令完成之后输出 rax 寄存器的内容:
1 | rax = 0x0000000000000001 |
表示刚刚 getCString:maxLength:encoding: 调用成功,返回 YES。此时把刚刚传入的 buffer 内容给 po 出来的话,可以看到:
1 | (lldb) po (char *)(0x00007ffee48ffba0) |
这就是从 @"BigDog" 解析得到的对应的 C 字符串 "BigDog"。
Part 4
接着是这一部分 <+101> ~ <+121>:

<+101> 处指令对 al 进行 test,al 寄存器就是 rax 的低八位,此时还存放着 getCString:maxLength:encoding: 方法的返回值,也就是 0x01。所以 <+101> 以及 <+103> 两个指令对应的伪代码可以表示为:
rax的低 32 位是eax,低 16 位是ax。
1 | if (!getCStringSuccess) { |
然后在 <+108> 处进行函数调用,输出 rdi 寄存器的值:
1 | (lldb) register read rdi |
别忘了 r15 里面仍然存着 getCString:maxLength:encoding: 时传入的 buffer 参数,也就是说这里进行了函数调用:strlen(buffer),函数调用之后得到的返回值存放在 rax 中,值为 6:
1 | (lldb) register read rax |
接着 <+113> 处执行了 cmpq 指令,等价于执行 %rax - %r14 两个运算,并且设置相应的标志位。别忘了,现在 %r14 寄存器里面仍然保存着前面 [@"BigDog" length] 的结果,也就是 6。结合 <+116> 处的 je 命令,这两个的指令对应的伪代码就是:
1 | if (resultFromLength == resultFromStrLen) { |
最后就是 <+118> 以及 <+121> 两处指令,由于程序运行到此处,上面的条件是成立的,会进行跳转,但为了继续研究后面的汇编指令,治理将 rflag 寄存器中的 ZF 标记为置为 0,让其不发生跳转:
1 | (lldb) register read rflags |
程序顺利运行到 <+118> 处指令。而经历了前面的类似探索,不难看出这里对应的伪代码就是:
1 | if (resultFromLength == 0) { |
综合上面内容,Part 4 这部分指令对应的伪代码可以表示为:
1 | // Part 4 Code |
小结
jump 1 实际上就是跳转到下面的第三个 if 结构,把代码合并一下:
1 | // Part 4 Code |
Part 5
接着看 <+123> 到 <+144> 部分代码,咋一看应该就是调用 characterAtIndex: 这个函数:

<+123> 处首先将 "characterAtIndex:" 字符串挪到 r13 寄存器中,后面 objc_msgSend 需要使用。
接着 <+130> 处执行了一个 xorl 按位异或的指令。它在这里的作用就相当于将 r15 寄存器的低 32 位清零,这里的 d 表示双字长,也就是 32 位。类似地后面对 ebx 进行了清空。接着后面的三个 movq 指令则是在准备后面 objc_msgSend 所需要的 3 个参数,其中第三个参数(rdx 中存放)也就时 characterAtIndex: 的第一个参数。输出这三个寄存器的值:
1 | (lldb) register read rdi rsi rdx |
于是这部分等价的 OC 代码为:
小结
1 | [@"BigDog" characterAtIndex:0]; |
Part 6
接着是 <+150> 到 <+161> 这部分代码:

首先把 ax 的值给读出来,它存放的是 Part 5 中的 [@"BigDog" characterAtIndex:0] 的返回值,也就是 "B":
1 | (lldb) register read ax |
所以 <+150> 以及 <+153> 两处的意思就是,如果 [@"BigDog" characterAtIndex:0] 为 0,就跳转到 0x10037b5e0 地址。
然后是 <+155> 处的一个 incq 指令,表示让 rbx 寄存器的内容递增,而这里 rbx 存放着 characterAtIndex: 的参数 index。
<+158> 处来了一个 cmpq 操作,前面提过,它会执行 %rbx - %r14,但不改变两个寄存器的内容,只会更新相关的标志位。而这里 r14 的内容是 6,仍保存着 [@"BigDog" length] 的结果。
另外 jb 指令表示 CF == 1 && ZF == 0 即 rbx < r14 转移。所以 <+158> 与 <+161> 处对应的伪代码可以是:
1 | // Part 6 Code |
而细心的你会发现,0x10037b5a1 这个地址就是前面 <+135> 处的指令。显然其实这是一个循环结构
小结
结合 Part 5 以及 Part 6,这两部分的伪代码(也就是 <+123> 到 <+161>)可以表示为:
1 | // Part 5 以及 Part 6 两部分的伪代码, |
Part 7
来到这里快要接近尾声了。现在来看看 <+163> 到 <+185> 这部分的指令:

一路走到这里,相信 666 的你可以看出 <+163> 到 <+173> 就是调用了方法 [@"BigDog" UTF8String]。
然后 <+179> 到 <+185> 就是把返回值放到 rdi 寄存器,然后调用 objc_lookUpClass 函数。在指令运行到 <+185> 处的 callq 指令打印 rdi 的值可以看到:
1 | (lldb) register read rdi |
小结
所以这部分指令对应的 OC 代码就是:
1 | // Part 7 Code |
Part 8
好嘞终于来到了最后一个部分:
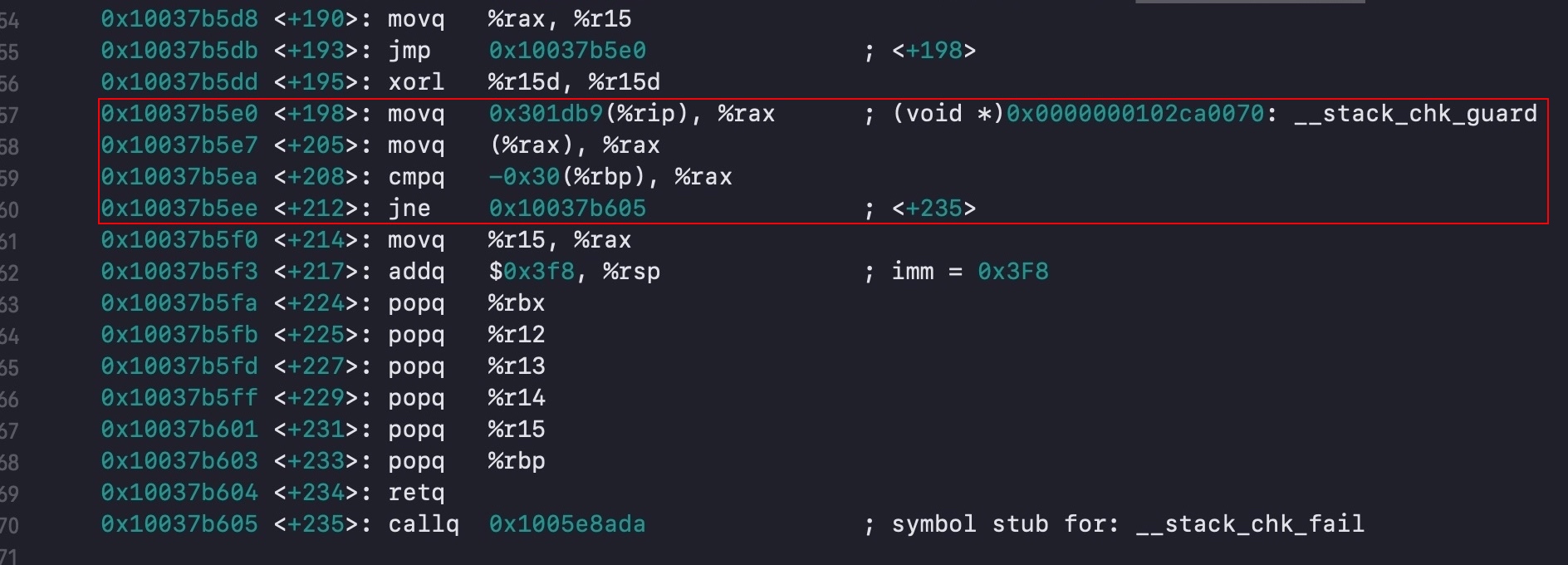
首先 <+190> 处将上面 objc_loopUpClass 的返回值放到了 r15 中,接着跳过 <+195> 的清零操作来到了 <+198>。红框部分是「栈溢出保护」的相关机制,如果 <+208> 处两个值不一样,就跳转到最后的 __stack_chk_fail 方法进行报错。暂时没太懂,先留一个坑。
栈溢出保护是一种缓冲区溢出攻击缓解手段,当函数存在缓冲区溢出攻击漏洞时,攻击者可以覆盖栈上的返回地址来让 shellcode 能够得到执行。当启用栈保护后,函数开始执行的时候会先往栈里插入 cookie 信息,当函数真正返回的时候会验证 cookie 信息是否合法,如果不合法就停止程序运行。攻击者在覆盖返回地址的时候往往也会将 cookie 信息给覆盖掉,导致栈保护检查失败而阻止 shellcode 的执行。来自这里。
最后 <+214> 设置一下 rax 寄存器的内容,用于向外返回值,也就是 BigDog 类对应的 objc_class 结构指针。后面剩下的就是出栈,以及恢复寄存器等操作了。
1 | (lldb) register read rax |
串联还原
现在我们要把所有部分都给串联起来。首先我们把跳转相关的逻辑给串起来,先用线把跳转相关的部分给串联起来:
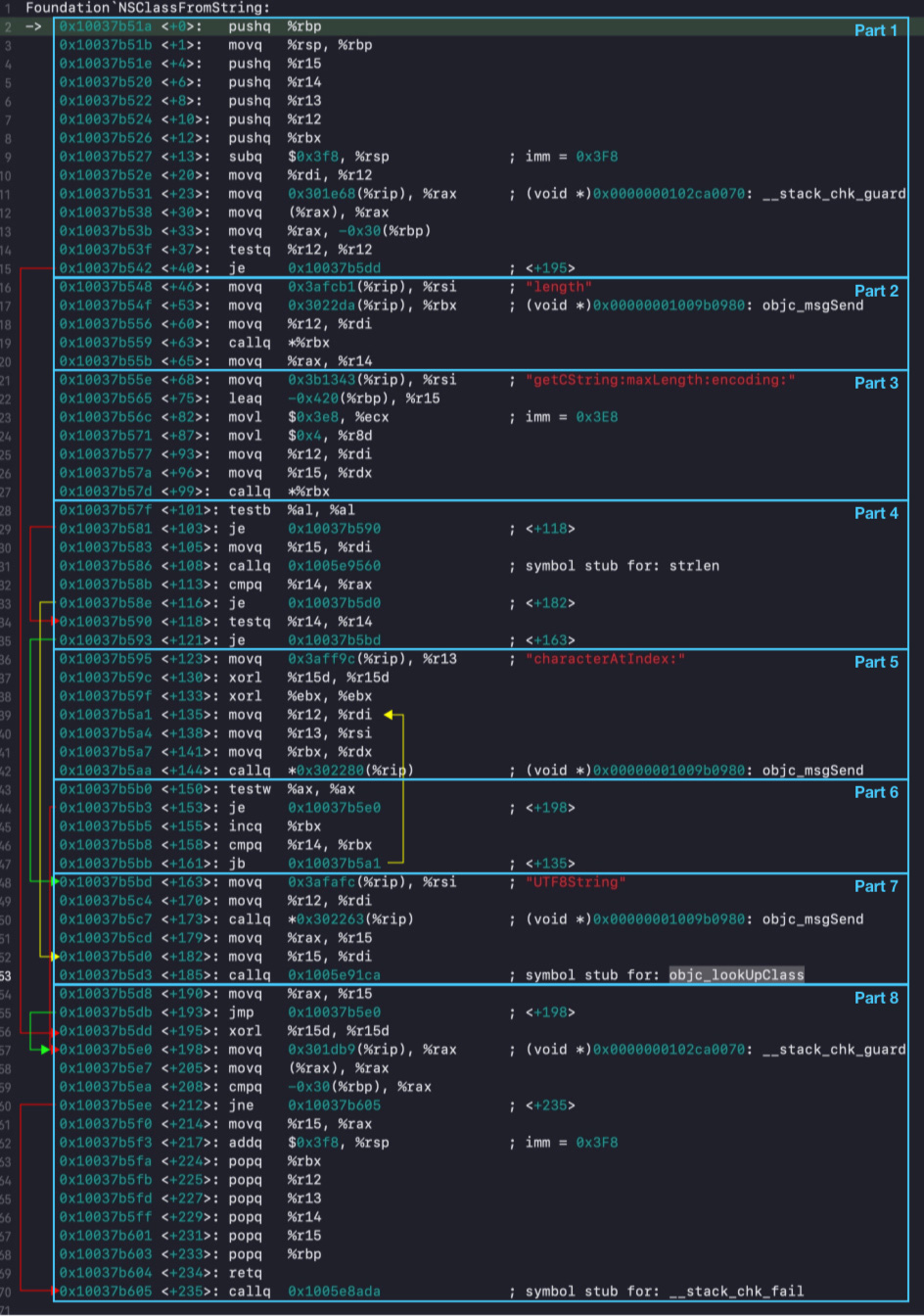
Part 1
接下来细看每处跳转,首先是 <+40> 处的跳转,它位于 Part 1 中。跳转到 <+195> 之后 xorl 指令会将 r15 寄存器清空,后面 <+214> 处把 r15 设到 rax 中,也就是说返回值被置为空,也就是 Nil。
小结
所以 Part 1 部分对应的 OC 代码实际上是:
1 | // Part 1 Code |
Part 2 & 3
接着回顾一下 Part 2 以及 Part 3 对应的 OC 代码:
1 | // Part 2 and Part 3 Code |
Part 4 & 7
Part 4 的跳转逻辑有 2 处,回顾一下 Part 4 的代码:
1 | // Part 4 Code |
然后是 Part 7 的代码,由于我们已经知道了 Part 8 就是函数返回的相关逻辑,所以 Part 7 代码可以补充下下面这样(多了 return 关键字):
1 | // Part 7 Code |
jump 1 的 0x10037b5bd 就是 Part 7 的 <+163> 处,进行方法调用 [@"BigDog" UTF8String]。
而 jump 2 的 0x10037b5d0 对应 Part 7 的 <+182> 处,是进行函数调用 objc_lookUpClass。又由于此时 r15 寄存器的值是 getCString:maxLength:encoding: 调用时传入的 buffer 参数。
小结
所以上面的代码可以转化为:
1 | // Part 4 Code |
嗯,看起来蠢蠢的。别急,后面会改的。
Part 5 & 6 + Part 4 & 7
根据前面的分段分析,Part 5 以及 Part 6 两部分实际上是一个循环结构:
1 | // Part 5 以及 Part 6 两部分的伪代码, |
而跳转到 0x10037b5e0 也就是 <+198> 实际也就意味着 return。并且由于在 Part 5 中的 <+130> 处对 r15 进行了清零,所以跳转到 return 之后,整个 NSClassFromString 也对外返回 Nil。也就是说这里上面的代码等价于下面:
1 | // Part 5 以及 Part 6 两部分的伪代码, |
现在要来分析 Part 5 & 6 在什么情况下会被执行到。对于这个问题,只需要看看上面的跳转逻辑图里面 Part 5 & 6 被多少个箭头跨越了即可。于是有下面结论:
- Part 1 中
aClassName != Nil是必要条件; - Part 4 中
!getCStringSuccess && resultFromLength != 0,代码会被执行; - 或者 Part 4 中
getCStringSuccess && resultFromLength != resultFromStrLen && resultFromLength != 0,代码会被执行;
接下来寻找 Part 5 & 6 代码的安放位置。Part 1 作为 NSClassFromString 的提前退出检查,这里 Part 5 & 6 代码位于 Part 1 的 if 结构之后,自然满足。
小结
最后看关于 Part 4 的两点,容易得到 Part 5 & 6 应该位于 Part 4 & 7 代码中下面注释的位置:
1 | // Part 4 Code |
Part 7 & 汇总
如果 Part 5 & 6 的循环结构没有发生跳转的话,后面就会直接执行 Part 7 代码,所以在上面两处循环后面要紧跟 Part 7 的两行代码。再把前面几个部分的代码合并起来,并且把代码精简一下,变量命名规范一下,我们就得到了 NSClassFromString 的源码了:
1 | Class _Nullable NSClassFromString(NSString *aClassName) { |
最后细心的你会发现,上面代码里面,打标记的两处代码完全相同,并且放到外层 if 结构后面代码逻辑是完全一样的,于是把它给抽出来。
小结
最后再整理一下条件的逻辑以及代码风格,得到 NSClassFromString 的实现如下:
1 | Class _Nullable NSClassFromString(NSString *aClassName) { |
对代码的一些理解也写在了上面。主要逻辑就是从 NSString 获取到 C 风格的字符串(以 \0 结尾),然后使用 objc_lookUpClass 查找对应的类实现。对不合法的字符串(非终止位置带有 \0)。以及由于 OC 中允许以非 Ascii 字符的方式定义类(如 Emoji),所以也需要对这种情况进行处理,得到相应的 C 字符串。
测试对比
下面实际测试一下,为了对比将上面推测得到的实现改名为 My_NSClassFromString:
1 | // 定义类 BigDog |
1 | // 两者均得到 BigDog |
总结
这应该是自大学毕业以来第一份完整阅读的汇编代码,整个读下来顿感高级语言编程的伟大,因为相比起汇编(更不要说机器指令),它们真的非常接近人类的语言表达。再度让我想起了一句话「代码是写给人看的」。
另外这次阅读过程中可以感受到了汇编代码的紧凑,以及其对效率的注重:比如用 xor 而不用 mov 来对寄存器进行清零,是为了减少最后编译得到的机器码的 size。但这又让我想起另一个事情:如果某处优化会损害代码的可读性,那么应该权衡一下这处优化是否值得。
后面会继续补上文首提到的该探索过程的其他部分。